React 常见面试题
在前面两个部分,写了 React 的基础使用,以及 React 源码的解析,包括了它的一些设计理念。但是对于面试来说,前面的内容,可能并不适合复习,知识点太过于零散了,所以在这个部分,会对一些常见的 React 面试题,做出我的回答。以供往后复习,也可以给大家一些参考。
写在前面
如果有什么回答错误的地方,欢迎您在 GitHub 上提 issue,或者直接添加我的微信:Ljc-10c ,进行沟通
React 为什么要造出 Hooks 呢?
在没有 Hooks 的时候,函数组件能够做的只是接受 Props、渲染 UI,以及触发父组件传过来的事件。所有的处理逻辑都要在类组件中写,这样会使得 Class 类组件内部错综复杂,每一个类组件都有一套独特的状态,相互之间不能复用,即便是使用 mixin 的复用方式也没有很好的解决。
类组件是之间的状态会随着功能的增强变得越来越臃肿,代码维护成本越来越高,不利于 Tree Shaking。
Hooks 出现的本质原因是,为了让函数式组件也能做类组件的事,有自己的状态,可以处理一些副作用、获取 Ref、也能够缓存数据,同时函数组件也能够让复用变得更加简单。
(追问)React Hooks 如何把状态保存起来?保存的信息存在了哪里?
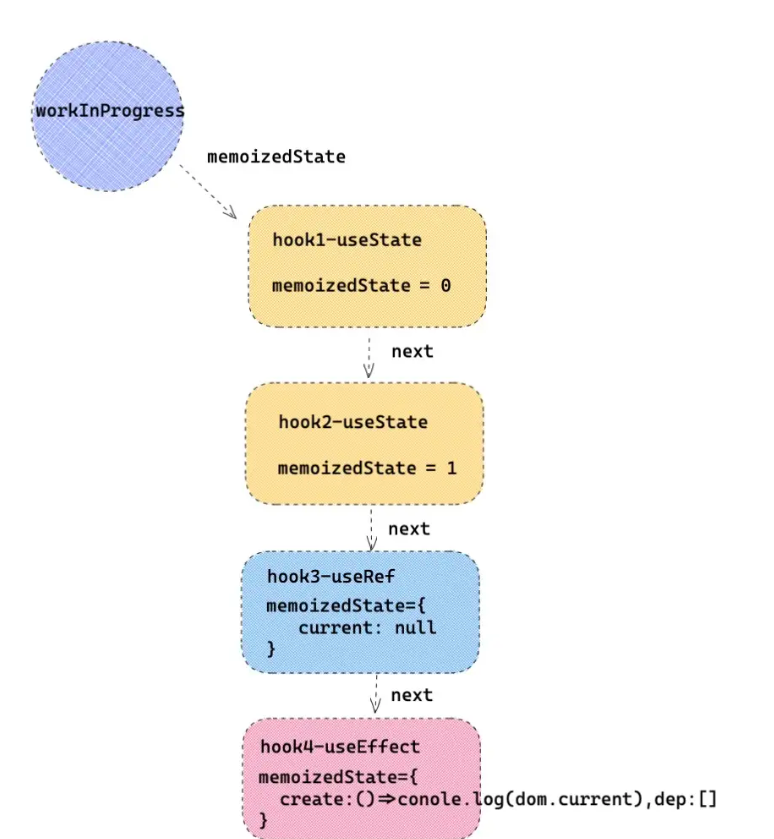
在 React 的 render 阶段 fiber 调和的过程中,当遇到了 Function Component 类型的 Fiber,就会用 updateFunctionComponent 来更新 Fiber,在 updateFunctionComponent 的内部会调用 renderWithHooks。在 renderWithHooks 中,会用 memoizedState 保存 hooks 信息。
Hooks 的信息会被保存到 Fiber 的 memoizedState 中,这个 memoizedState 是一个链表,这个链表的连接关系就是 Hooks 的调用顺序,链表的每个节点都是一个 hooks 的信息,这个 hooks 对象中,保存着当前 hooks 的信息,不同 hooks 保存的形式不同
(追问)为什么 React Hooks 不能写在条件语句中
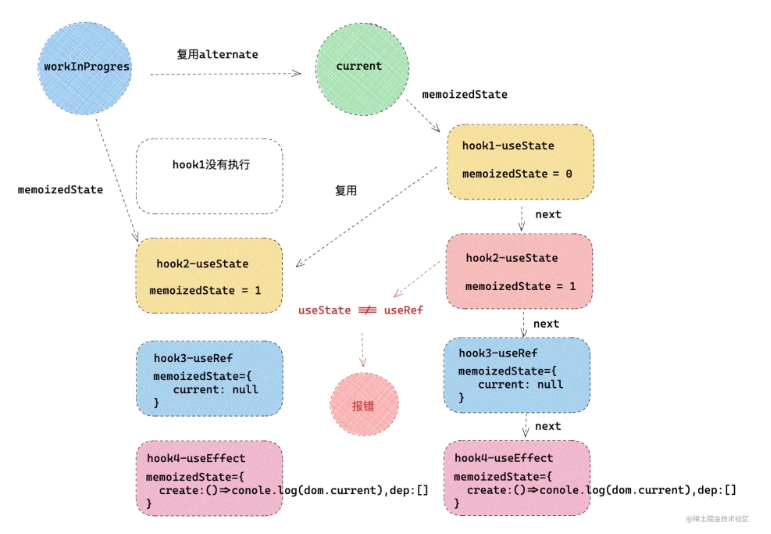
因为在 React hooks 更新的过程中,首先会从 workInProgress.alternate 中取出对应的 hook,**这个取出其实是按照顺序的,**然后根据这个 hooks 复制一份,形成新的 hooks 链表关系。
根据这个规则,如果在 if 条件语句中,使用 hooks,有可能导致 前后的 hooks 数量不一致,在复用 hooks 的过程中,会出现错乱的问题,也就导致了前后状态不一致的问题。
React Hooks 的大致原理?
我的回答
首先我觉得这个问题,可以先谈谈为什么 react 要造出 hooks,因为知道了为什么要做,我们就能知道该怎么做了。在没有 hooks 之前,函数式组件没有自己的状态,只能接受 props,渲染 ui,传递事件。hooks 的出现让函数式组件有了自己的状态。
那么可以想想类组件的状态是如何保存的,它是保存在类组件的实例上。
那么函数式组件要有自己的状态,那就需要有地方能够保存它的状态,也就是 React Fiber,在每个 element 对应的 fiber 节点上 的 memoizedState 字段,就是用来保存 hooks 信息的。在类组件中用来保存 state 状态。
React 在 fiber 的调和阶段,将所有的 function component 中调用的 hooks,注册到 memoizedState 上,与 fiber 形成关联
对于不同的 hooks 挂载的 hook 信息不同,要更新 hooks 可以通过返回的方法 dispatchAction 来进行更新,它会创建一个 update,然后把它放到待更新 pending 队列中。
然后判断如果当前的 fiber 正在更新,那么也就不需要再更新了。 反之,说明当前 fiber 没有更新任务,那么会拿出上一次 state 和 这一次 state 进行对比,如果相同,那么直接退出更新。如果不相同,那么发起更新调度任务。这就解释了,为什么函数组件 useState 改变相同的值,组件不更新了。
React Hooks 解决了什么问题
TIP
前面也有提到很多,react hooks 的出现主要是为了解决函数式组件没有状态的问题,同时也解决了类组件状态和 ui 逻辑耦合导致难以复用的问题。复杂的类组件的逻辑会非常多,生命周期很多,组件难以理解,维护和拆分重构都非常困难。
什么是虚拟 DOM,它的作用是什么?
TIP
虚拟 DOM 是 React 在内存中描述节点的一种形态,我们编写的 JSX 可以说是一个语法糖,它通过 react 调和之后会形成一棵虚拟 DOM Tree,也可以理解为在内存中存在的形态。它反映的是真实 DOM 节点,在内存中用一个 Object 来描述。
在 DOM 节点数量少的情况下,直接操作真实 DOM 问题不大,浏览器不会出现很大的消耗。但是在节点非常多的情况下,页面触发 10 次更新,浏览器会进行 10 次的 layout 和 paint 的流程,非常可能出现卡顿的情况。虚拟 DOM 的出现就是解决这样的问题,它不会直接将更新直接应用在真实 DOM 节点上,而是通过虚拟 DOM 的计算,算出本次操作的更新带来了那样的结果,再将更新一次性应用在对应需要更新的节点上,避免了大量无谓的计算。
但是它的性能消耗在于需要做一次 Diff,找出变更。
同时虚拟 DOM 的抽象,也让跨平台变的更加容易,一套虚拟 DOM 可以映射到多套 DSL 上。
React Diff 的原理?
React 为什么需要 Diff?
useState 为什么用数组来声明,为什么不用对象?
数组解构是按照顺序的,对象是按名字的
React cloneElement 和 createElement 的区别?
React 中的 key 的作用是什么?
React 的 render 函数是如何渲染的,是如何更新的?
我的回答
这个问题可以从首次渲染和更新渲染两个阶段来理解 React 的 render 函数工作原理。
一、首次渲染流程
当我们调用 ReactDOM.render(element, container) 时,React 会进行以下步骤:
1. 创建 Root Fiber
// 创建根 Fiber 节点
let rootFiber = {
node: container, // 真实 DOM 容器节点
props: { children: vnode } // vnode 是我们传入的 React 元素
}根 Fiber 是整个 Fiber 树的起点,它关联着真实的 DOM 容器节点。
2. 启动调度更新
const render = (vnode, node) => {
currentDom = node.firstChild; // 记录当前 DOM(用于 SSR 水合)
let rootFiber = {
node,
props: { children: vnode }
};
update(rootFiber); // 调度更新
};update 函数会将 fiber 标记为脏节点,并将其加入调度队列:
const update = (fiber) => {
if (!fiber.dirty) {
fiber.dirty = true;
schedule(() => reconcile(fiber)); // 进入调度器
}
};3. Fiber 协调过程 (Reconcile)
协调过程是一个可中断的循环,会遍历整个 Fiber 树:
const reconcile = (fiber) => {
while (fiber && !shouldYield()) { // 可中断,避免长时间阻塞
fiber = capture(fiber);
}
return fiber ? reconcile.bind(null, fiber) : null;
};在 capture 阶段,会区分函数组件和原生 DOM 元素:
const capture = (fiber) => {
fiber.isComp = isFn(fiber.type); // 判断是否是组件
if (fiber.isComp) {
updateHook(fiber); // 处理函数组件
} else {
updateHost(fiber); // 处理原生元素
}
return fiber.child || sibling(fiber); // 深度优先遍历
};4. 处理函数组件 (updateHook)
对于函数组件,会执行组件函数,获取返回的 children:
const updateHook = (fiber) => {
resetCursor(); // 重置 hooks 游标
resetFiber(fiber); // 设置当前 fiber 上下文
fiber.node = fiber.node || fragment(fiber); // 创建注释节点占位
try {
let children = fiber.type(fiber.props); // 执行组件函数
reconcileChildren(fiber, simpleVnode(children));
} catch (e) {
// 处理 Suspense 和 ErrorBoundary
}
};5. 处理原生元素 (updateHost)
对于原生 DOM 元素,会创建真实 DOM 节点:
const updateHost = (fiber) => {
if (!fiber.node) {
if (fiber.type === "svg") fiber.lane |= TAG.SVG;
fiber.node = createElement(fiber); // 创建 DOM 节点
}
reconcileChildren(fiber, fiber.props.children);
};
const createElement = (fiber) => {
const dom = fiber.type === "#text"
? document.createTextNode("")
: fiber.lane & TAG.SVG
? document.createElementNS("http://www.w3.org/2000/svg", fiber.type)
: document.createElement(fiber.type);
updateElement(dom, {}, fiber.props); // 设置属性
return dom;
};6. 协调子元素 (reconcileChildren)
这个过程会对比新旧子节点,生成操作标记:
const reconcileChildren = (fiber, children) => {
let aCh = fiber.kids || []; // 旧的子节点
let bCh = fiber.kids = arrayfy(children); // 新的子节点
const actions = diff(aCh, bCh); // Diff 算法
for (let i = 0; i < bCh.length; i++) {
const child = bCh[i];
child.action = actions[i]; // INSERT/UPDATE/MOVE/REMOVE
child.parent = fiber;
// 构建 sibling 链表
}
};7. Commit 阶段
协调完成后,进入 commit 阶段,将变更应用到真实 DOM:
const commit = (fiber) => {
let { op, ref, cur } = fiber.action || {};
let parent = fiber?.parent?.node;
if (op & TAG.INSERT || op & TAG.MOVE) {
parent.insertBefore(cur?.node, ref?.node); // 插入节点
}
if (op & TAG.UPDATE) {
updateElement(fiber.node, fiber.alternate?.props || {}, fiber.props);
}
commit(fiber.sibling); // 递归处理兄弟节点
};二、更新渲染流程
当组件状态发生变化时(如调用 setState),会触发更新:
1. 触发更新
// useState 的 setState 实现
hook[1] = (value) => {
let v = isFn(value) ? value(hook[0]) : value;
if (hook[0] !== v) { // 值变化才更新
hook[0] = v;
update(current); // 调度当前 fiber 更新
}
};2. 复用与对比
更新时会复用之前的 Fiber 节点:
function clone(a, b) {
b.hooks = a.hooks; // 复用 hooks
b.ref = a.ref; // 复用 ref
b.node = a.node; // 复用 DOM 节点
b.kids = a.kids; // 复用子节点
a.flag = TAG.REPLACE;
b.alternate = a; // 指向旧 fiber
}3. Diff 算法
React 使用双端 Diff 算法优化性能:
const diff = (aCh, bCh) => {
let aHead = 0, bHead = 0;
let aTail = aCh.length - 1, bTail = bCh.length - 1;
// 1. 从尾部开始比较
while (aHead <= aTail && bHead <= bTail) {
if (!same(aCh[aTail], bCh[bTail])) break;
clone(aCh[aTail], bCh[bTail]);
// 标记为 UPDATE
}
// 2. 从头部开始比较
while (aHead <= aTail && bHead <= bTail) {
if (!same(aCh[aHead], bCh[bHead])) break;
clone(aCh[aHead], bCh[bHead]);
// 标记为 UPDATE
}
// 3. 处理中间乱序部分
// 使用 key 来快速查找可复用节点
// 标记为 INSERT/MOVE/REMOVE
};4. 增量更新
只更新发生变化的属性:
const updateElement = (dom, oldProps, newProps) => {
jointIter(oldProps, newProps, (name, oldVal, newVal) => {
if (oldVal === newVal) return; // 未变化跳过
if (name === "style") {
// 只更新变化的样式
jointIter(oldVal, newVal, (styleKey, oldStyle, newStyle) => {
if (oldStyle !== newStyle) {
dom.style[styleKey] = newStyle || "";
}
});
} else if (name.startsWith("on")) {
// 更新事件监听
dom.removeEventListener(name.slice(2).toLowerCase(), oldVal);
dom.addEventListener(name.slice(2).toLowerCase(), newVal);
} else {
dom[name] = newVal || "";
}
});
};三、关键优化点
- 时间切片:
shouldYield()检查是否超时,避免长时间阻塞主线程 - 跳过无变化节点: 通过
same()函数比较 type 和 key,快速判断是否可复用 - 批量更新: 通过调度器收集多个更新,统一执行
- Fiber 架构: 可中断的链表结构,支持优先级调度
总结
React 的 render 过程分为两大阶段:
- Render 阶段(可中断): 构建 Fiber 树,通过 Diff 算法标记变更,这个阶段是纯计算,不操作 DOM
- Commit 阶段(不可中断): 将标记的变更一次性应用到真实 DOM,完成渲染
更新时会尽可能复用已有的 Fiber 和 DOM 节点,只更新发生变化的部分,这就是 React 高效的原因。
React 的调度器(Scheduler)是如何实现时间切片的?
我的回答
React 的时间切片(Time Slicing)是实现并发渲染的核心机制,它可以让 React 在执行长时间任务时不阻塞浏览器,保持页面的流畅性。
一、时间切片的基本原理
核心思想: 将一个长任务拆分成多个小任务,每个小任务执行完后检查是否需要让出主线程给浏览器处理用户交互、渲染等高优先级任务。
// 时间阈值,默认 5ms
const threshold = 5;
let deadline = 0;
// 检查是否应该让出主线程
const shouldYield = () => {
return getTime() >= deadline;
};
const getTime = () => performance.now();二、任务调度队列
React 维护一个任务队列,使用最小堆数据结构来管理不同优先级的任务:
const queue = []; // 任务队列
// 将任务加入队列
const schedule = (callback) => {
queue.push({ callback });
startTransition(flush); // 开始调度
};三、异步调度实现
React 使用多种方式实现异步调度,优先级从高到低:
1. queueMicrotask (最高优先级)
const task = (pending) => {
const cb = () => transitions.splice(0, 1).forEach((c) => c());
// 非 pending 状态优先使用微任务
if (!pending && typeof queueMicrotask !== "undefined") {
return () => queueMicrotask(cb);
}
// ... 降级方案
};2. MessageChannel (中等优先级)
if (typeof MessageChannel !== "undefined") {
const { port1, port2 } = new MessageChannel();
port1.onmessage = cb;
return () => port2.postMessage(null);
}MessageChannel 的优势:
- 宏任务,不会阻塞微任务队列
- 比 setTimeout 更快,没有 4ms 延迟
- 可以在下一帧之前执行
3. setTimeout (降级方案)
return () => setTimeout(cb);四、任务执行循环
flush 函数是调度器的核心,负责循环执行任务:
const flush = () => {
deadline = getTime() + threshold; // 设置本次执行的截止时间
let job = peek(queue); // 获取队列头部任务
// 循环执行任务,直到超时或队列为空
while (job && !shouldYield()) {
const { callback } = job;
job.callback = null;
const next = callback(); // 执行任务
if (next) {
// 如果任务返回了新的回调,说明还有后续工作
job.callback = next;
} else {
// 任务完成,移出队列
queue.shift();
}
job = peek(queue);
}
// 如果还有任务,继续调度
job && (translate = task(shouldYield())) && startTransition(flush);
};五、可中断的 Reconcile 过程
React 的协调过程天然支持中断:
const reconcile = (fiber) => {
while (fiber && !shouldYield()) { // 每次循环检查是否超时
fiber = capture(fiber); // 处理当前 fiber
}
// 如果超时且还有未完成的 fiber,返回一个闭包继续执行
return fiber ? reconcile.bind(null, fiber) : null;
};工作流程:
- 进入
reconcile,设置 deadline - 处理 fiber 节点(capture)
- 每处理完一个节点,检查
shouldYield() - 如果超时,返回闭包保存当前进度
- 调度器稍后会继续执行这个闭包
六、优先级管理
通过 startTransition 可以标记低优先级更新:
const transitions = []; // 过渡任务队列
const startTransition = (cb) => {
transitions.push(cb) && translate();
};
let translate = task(false); // 异步执行函数七、实际应用示例
function App() {
const [list, setList] = useState([1, 2, 3]);
const handleClick = () => {
// 这个更新会被调度器处理
setList(list.concat(4));
// 1. 触发 update(fiber)
// 2. fiber.dirty = true
// 3. schedule(() => reconcile(fiber))
// 4. 进入任务队列
// 5. flush 循环执行,可能被中断多次
// 6. 最终 commit 到 DOM
};
return (
<div>
{list.map(d => <span>{d}</span>)}
<button onClick={handleClick}>+</button>
</div>
);
}八、时间切片的优势
- 不阻塞用户交互: 每 5ms 检查一次,让出主线程
- 平滑的动画: 浏览器有时间执行 requestAnimationFrame
- 更好的响应性: 高优先级任务(如用户输入)可以插队
- 可中断可恢复: Fiber 架构支持保存进度,随时恢复
九、关键设计
为什么是 5ms?
- 一帧是 16.6ms (60fps)
- 留给 React 5ms,剩余时间给浏览器布局、绘制
- 保证每帧都有足够时间响应用户
为什么用 MessageChannel?
- setTimeout 有 4ms 的最小延迟限制
- requestIdleCallback 兼容性差,且只在空闲时执行
- MessageChannel 立即执行,不受帧限制
总结
React 的时间切片通过以下机制实现:
- 任务队列: 管理待执行的更新任务
- 时间阈值: 每 5ms 检查一次是否需要让出主线程
- 可中断循环: Reconcile 过程可以随时暂停和恢复
- 异步调度: 使用 MessageChannel/微任务实现非阻塞调度
- Fiber 架构: 链表结构天然支持断点续传
这种设计让 React 即使在处理大量更新时也能保持页面流畅,这就是并发模式的基础。
React Fiber 架构解决了什么问题?
我的回答
React Fiber 架构是 React 16 引入的全新协调引擎,它彻底重写了 React 的核心算法。要理解 Fiber 解决了什么问题,需要先看看之前的 Stack Reconciler 有什么局限性。
一、Stack Reconciler 的问题
在 Fiber 之前,React 使用的是递归的协调算法:
// 旧的递归方式(简化版)
function reconcile(element, container) {
// 创建/更新节点
const dom = createOrUpdateDOM(element);
// 递归处理子节点
element.children.forEach(child => {
reconcile(child, dom); // 深度优先,无法中断
});
// 挂载到父节点
container.appendChild(dom);
}核心问题:
- 同步且不可中断: 一旦开始,必须完成整棵树的协调
- 长时间占用主线程: 大组件树会导致页面卡顿
- 无法区分优先级: 所有更新同等对待
- 调用栈很深: 递归层级深,调试困难
二、Fiber 的核心设计
Fiber 将协调工作从递归改为循环+链表遍历:
// Fiber 节点结构
{
type: 'div', // 元素类型
props: {...}, // 属性
node: DOMElement, // 真实 DOM
// 链表关系
child: Fiber, // 第一个子节点
sibling: Fiber, // 下一个兄弟节点
parent: Fiber, // 父节点
// 状态管理
alternate: Fiber, // 上一次的 Fiber(双缓冲)
hooks: {...}, // hooks 链表
action: {...}, // 待执行的操作标记
// 调度相关
dirty: boolean, // 是否需要更新
lane: number, // 优先级通道
mode: number, // 渲染模式(OFFSCREEN等)
}三、Fiber 解决的核心问题
1. 可中断的协调过程
通过循环替代递归,每次循环可以检查是否需要暂停:
const reconcile = (fiber) => {
while (fiber && !shouldYield()) { // 可随时中断
fiber = capture(fiber); // 处理当前节点
}
// 超时则返回闭包,保存进度
return fiber ? reconcile.bind(null, fiber) : null;
};对比旧方式:
// 旧递归: 无法中断,必须完成
function oldReconcile(node) {
updateNode(node);
node.children.forEach(oldReconcile); // 一直递归到底
}2. 双缓冲机制
Fiber 使用 current 和 workInProgress 两棵树:
function clone(a, b) {
b.hooks = a.hooks; // 复用 hooks
b.ref = a.ref; // 复用 ref
b.node = a.node; // 复用 DOM 节点
b.alternate = a; // 指向旧 fiber,形成双缓冲
}好处:
- 在内存中构建新树,不影响当前页面
- 出错可以回滚到 current 树
- 对比新旧树实现精确更新
3. 优先级调度
通过 lane 模型管理不同优先级的更新:
// 不同类型的更新可以有不同优先级
fiber.lane |= TAG.SVG; // SVG 相关
fiber.mode & MODE.OFFSCREEN // Suspense 离屏渲染
// Diff 时可以跳过低优先级节点
if (fiber.mode & MODE.OFFSCREEN) {
return commitSibling(fiber.sibling); // 跳过渲染
}4. 增量渲染
Fiber 将渲染分为两个阶段:
// Render 阶段(可中断,纯计算)
const capture = (fiber) => {
fiber.isComp = isFn(fiber.type);
if (fiber.isComp) {
updateHook(fiber); // 执行组件,标记变更
} else {
updateHost(fiber); // 创建/复用 DOM
}
return fiber.child || sibling(fiber);
};
// Commit 阶段(不可中断,操作 DOM)
const commit = (fiber) => {
let { op } = fiber.action || {};
if (op & TAG.INSERT) {
parent.insertBefore(cur.node, ref.node); // 真正插入
}
if (op & TAG.UPDATE) {
updateElement(fiber.node, oldProps, newProps); // 真正更新
}
};5. 错误边界和 Suspense
Fiber 架构天然支持错误捕获和异步渲染:
const updateHook = (fiber) => {
try {
let children = fiber.type(fiber.props);
reconcileChildren(fiber, children);
} catch (e) {
if (e instanceof Promise) {
// 捕获 Promise,进入 Suspense 流程
return suspenseRender(fiber, e).sibling;
} else {
// 捕获错误,进入 ErrorBoundary 流程
return errorBoundaryRender(fiber, e).child;
}
}
};四、Fiber 遍历策略
Fiber 使用深度优先 + 兄弟链表的遍历方式:
const capture = (fiber) => {
// 处理当前节点
updateNode(fiber);
// 1. 优先处理子节点
if (fiber.child) return fiber.child;
// 2. 子节点处理完,处理兄弟节点
if (fiber.sibling) return fiber.sibling;
// 3. 兄弟节点也没有,回到父节点的兄弟
let parent = fiber.parent;
while (parent) {
if (parent.sibling) return parent.sibling;
parent = parent.parent;
}
return null; // 遍历完成
};树结构示例:
App
|
child
|
div ----sibling----> span
| |
child child
| |
p1 --sibling--> p2 text遍历顺序: App → div → p1 → p2 → span → text
五、性能对比
旧架构(Stack):
渲染 10000 个节点 → 阻塞主线程 100ms → 页面卡死
用户点击按钮 → 需要等待渲染完成 → 体验差新架构(Fiber):
渲染 10000 个节点 → 分 20 个切片 → 每片 5ms
每 5ms 让出主线程 → 处理用户交互 → 页面流畅六、实际案例
function HeavyComponent() {
const [count, setCount] = useState(0);
// 渲染 10000 个元素
const items = Array.from({ length: 10000 }, (_, i) => (
<div key={i}>{i}</div>
));
return (
<div>
<button onClick={() => setCount(count + 1)}>
点击次数: {count}
</button>
{items}
</div>
);
}Stack Reconciler: 点击按钮后,必须等待 10000 个 div 全部更新完才能看到 count 变化,可能需要几百毫秒。
Fiber: 点击按钮后,count 立即更新(高优先级),列表在后台慢慢渲染(低优先级),用户感觉很流畅。
总结
Fiber 架构解决的核心问题:
- 可中断性: 从递归改为循环,随时可以暂停恢复
- 优先级调度: 区分高优先级(用户输入)和低优先级(数据展示)
- 增量渲染: 将工作分片执行,不阻塞主线程
- 双缓冲: 在后台构建新树,一次性切换,避免闪烁
- 错误处理: 支持 ErrorBoundary 和 Suspense
Fiber 让 React 从同步渲染升级为并发渲染,这是 React 18 并发特性的基石。
React 中的事件是如何处理的?为什么要用合成事件?
我的回答
React 没有直接把事件绑定到 DOM 元素上,而是实现了一套合成事件(SyntheticEvent) 系统。理解事件处理需要从事件绑定、事件委托、事件对象三个方面来看。
一、事件绑定原理
在更新 DOM 属性时,React 会特殊处理以 on 开头的属性:
const updateElement = (dom, oldProps, newProps) => {
jointIter(oldProps, newProps, (name, oldVal, newVal) => {
if (oldVal === newVal) return;
// 识别事件处理器
if (name[0] === "o" && name[1] === "n") {
name = name.slice(2).toLowerCase(); // onClick -> click
// 移除旧监听器
if (oldVal) {
dom.removeEventListener(name, oldVal);
}
// 添加新监听器
dom.addEventListener(name, newVal);
}
// ... 其他属性处理
});
};关键点:
- 截取事件名:
onClick→click - 转小写:
onClick→click(统一处理) - 直接绑定到 DOM 元素上
二、为什么需要合成事件?
1. 抹平浏览器差异
不同浏览器的事件对象有差异:
// 原生事件的兼容性问题
element.addEventListener('click', (e) => {
const target = e.target || e.srcElement; // IE 用 srcElement
e.preventDefault ? e.preventDefault() : (e.returnValue = false);
e.stopPropagation ? e.stopPropagation() : (e.cancelBubble = true);
});
// React 合成事件统一接口
<button onClick={(e) => {
e.preventDefault(); // 所有浏览器都一样
e.stopPropagation();
}}>Click</button>2. 事件委托优化
React 17 之前,所有事件都委托到 document:
// React 内部实现(简化版)
document.addEventListener('click', (nativeEvent) => {
// 从事件触发的元素开始,向上查找
let fiber = getFiberFromDOM(nativeEvent.target);
// 收集路径上所有的 onClick 处理器
const listeners = [];
while (fiber) {
if (fiber.props.onClick) {
listeners.push(fiber.props.onClick);
}
fiber = fiber.parent;
}
// 模拟捕获和冒泡
listeners.forEach(listener => listener(syntheticEvent));
});好处:
- 减少内存占用: 10000 个按钮只需要 1 个事件监听器
- 动态节点支持: 新增的 DOM 自动支持事件
3. 事件池(Event Pooling)
React 17 之前使用事件池复用事件对象:
// 简化的事件池实现
const eventPool = [];
function getPooledEvent(nativeEvent) {
const syntheticEvent = eventPool.pop() || {};
syntheticEvent.nativeEvent = nativeEvent;
syntheticEvent.target = nativeEvent.target;
// ... 复制其他属性
return syntheticEvent;
}
function releasePooledEvent(event) {
// 清空事件对象,放回池中
Object.keys(event).forEach(key => event[key] = null);
eventPool.push(event);
}注意: React 17+ 已经移除事件池,因为现代浏览器性能足够好。
三、合成事件的结构
// React 合成事件对象
const syntheticEvent = {
nativeEvent: MouseEvent, // 原生事件对象
type: 'click', // 事件类型
target: HTMLElement, // 触发事件的元素
currentTarget: HTMLElement, // 当前处理事件的元素
// 统一的方法
preventDefault: () => {...},
stopPropagation: () => {...},
persist: () => {...}, // 持久化事件(17之前)
// 其他原生事件属性
bubbles: true,
cancelable: true,
// ...
};四、事件执行流程
// 用户点击按钮
<div onClick={handleDivClick}>
<button onClick={handleButtonClick}>
Click Me
</button>
</div>
// 实际执行流程:
// 1. 原生事件触发: button 被点击
// 2. 事件冒泡到 document(或 root)
// 3. React 捕获原生事件
// 4. 创建合成事件对象
// 5. 模拟捕获阶段(如果有 onClickCapture)
// 6. 模拟冒泡阶段:
// - 先执行 handleButtonClick
// - 再执行 handleDivClick
// 7. 释放事件对象(旧版)五、阻止冒泡的特殊性
function App() {
const handleButtonClick = (e) => {
e.stopPropagation(); // 阻止合成事件冒泡
console.log('Button clicked');
};
const handleDivClick = () => {
console.log('Div clicked'); // 不会执行
};
return (
<div onClick={handleDivClick}>
<button onClick={handleButtonClick}>Click</button>
</div>
);
}
// 但是!!!
document.addEventListener('click', () => {
console.log('Document clicked'); // 仍然会执行!
});原因: e.stopPropagation() 只阻止 React 合成事件的冒泡,不影响原生事件。
如果要阻止原生冒泡:
const handleButtonClick = (e) => {
e.nativeEvent.stopImmediatePropagation(); // 阻止原生冒泡
};六、React 17 的改进
改变 1: 事件委托位置
// React 16: 委托到 document
document.addEventListener('click', handler);
// React 17+: 委托到 root 容器
const root = document.getElementById('root');
root.addEventListener('click', handler);好处:
- 支持微前端(多个 React 应用共存)
- 更容易和非 React 代码集成
改变 2: 移除事件池
// React 16: 异步访问会出错
function handleClick(e) {
setTimeout(() => {
console.log(e.type); // ❌ null (事件被清空了)
}, 100);
}
// React 17+: 可以正常访问
function handleClick(e) {
setTimeout(() => {
console.log(e.type); // ✅ 'click'
}, 100);
}七、特殊事件处理
1. onChange 的特殊性
// 原生 input 的 change 只在失去焦点时触发
<input onchange="..." />
// React 的 onChange 在每次输入时触发
<input onChange={(e) => console.log(e.target.value)} />
// React 内部实际监听的是 input 事件
input.addEventListener('input', handleChange);2. onScroll 和 onResize
这些事件不冒泡,React 会直接绑定到元素上,而不是委托:
if (name === 'scroll' || name === 'resize') {
// 直接绑定,不委托
dom.addEventListener(name, handler);
}八、性能优化建议
1. 避免在渲染中创建新函数
// ❌ 每次渲染都创建新函数
<button onClick={() => handleClick(id)}>Click</button>
// ✅ 使用 useCallback 缓存
const handleClickWithId = useCallback(() => handleClick(id), [id]);
<button onClick={handleClickWithId}>Click</button>
// ✅ 或使用事件委托
<button data-id={id} onClick={handleClick}>Click</button>
function handleClick(e) {
const id = e.currentTarget.dataset.id;
}2. 使用事件委托减少监听器
// ❌ 1000 个监听器
{list.map(item => (
<div onClick={() => handleClick(item.id)}>{item.name}</div>
))}
// ✅ 只有 1 个监听器
<div onClick={handleClick}>
{list.map(item => (
<div data-id={item.id}>{item.name}</div>
))}
</div>总结
React 合成事件的核心特点:
- 统一接口: 抹平浏览器差异,提供一致的 API
- 事件委托: 减少内存占用,优化性能
- 可控的事件流: React 完全控制事件的捕获和冒泡
- 与 Fiber 集成: 支持优先级调度和并发渲染
合成事件让 React 在保证性能的同时,提供了更好的跨浏览器兼容性和开发体验。
React 18 并发模式和调度器
React并发模式是什么?
"React 18的并发模式,简单说就是让React变得更智能了。以前React一旦开始渲染就必须一口气完成,现在可以随时停下来,让浏览器处理用户输入,等空闲了再继续。"
自动批处理有什么变化?
"React 17的时候,只有在onClick这种事件里才会批处理。如果在setTimeout或者Promise里写setState,那每个setState都会重新渲染一次。但是React 18就更智能了,不管你在哪里setState,React都会自动帮你批处理,攒在一起只渲染一次。"
// React 18自动批处理
setTimeout(() => {
setCount(c => c + 1); // 不会立即渲染
setFlag(f => !f); // 不会立即渲染
// 只渲染一次
}, 0);调度器是做什么的?
"调度器就像是React的'大脑',负责决定什么时候做什么事。它知道哪些更新比较重要,需要立即处理,哪些不那么急,可以等一等。"
"比如用户在输入框打字,这个就要立即响应。但是搜索结果的更新就可以稍微等一等,这样用户体验更好。"
时间分片是什么原理?
"时间分片就是把大的任务拆成小块,每5ms检查一次是否需要让出主线程给浏览器。这样即使用户在React正在处理大量数据时点击按钮,也不会感觉卡顿。"
Transition怎么用?
"Transition就是React提供的一个工具,用来区分紧急更新和非紧急更新:"
const handleChange = (e) => {
// 紧急更新:立即显示用户输入
setInputValue(e.target.value);
// 非紧急更新:搜索结果可以延迟
startTransition(() => {
setSearchQuery(e.target.value);
});
};开启并发模式
"React 18用createRoot就自动开启并发模式了,不需要额外配置。"
import { createRoot } from 'react-dom/client';
const root = createRoot(document.getElementById('root'));
root.render(<App />);React Fiber架构
Fiber解决了什么问题?
"在Fiber之前,React用的是递归方式,一旦开始渲染就必须完成整棵树,如果组件很多就会卡死页面。"
"Fiber把递归改成了循环+链表,可以随时中断和恢复。就像打游戏一样,以前必须一关打完才能存档,现在随时可以暂停,下次继续。"
双缓冲是什么意思?
"Fiber用了两棵树:current树是当前显示的,workInProgress树是在内存里构建的。等新树构建完成了,一下子切换过去。这样就不会出现页面闪烁的问题。"
优先级车道
"React 18给不同类型的更新分配了不同的优先级:用户交互最高,数据更新中等,统计数据最低。就像高速公路有快车道慢车道一样。"
两阶段渲染
"Render阶段是可中断的,只计算,不操作DOM。Commit阶段是不可中断的,把计算结果真正应用到页面上。这样既能保证响应性,又能确保最终结果正确。"
总结要点
- 并发模式让React渲染可中断,不阻塞用户交互
- 自动批处理提升性能,减少不必要的渲染
- 调度器智能分配任务优先级
- 时间分片防止长时间占用主线程
- Fiber架构是这一切的技术基础